マルチビーム測深:CUBE処理とは何か?
参考文献
- CUBE User’s Manual, version 1.13 Brian Calder Center for Coastal and Ocean Mapping and NOAA/UNH Joint Hydrographic Center University of New Hampshire
東陽テクニカ EMC特機技術部
はじめに
水路測量や海底地形調査ではマルチビーム測深機を使用し、川底や海底などの目に見えない部分を調査します。マルチビーム測深機は扇形に音波を発射し、複数の測深データを1度に受信します。海底面を面的に計測することができるため、効率的に海底地形調査を行うことが可能です。これらの取得したデータにノイズ処理や水中音速度補正、測位・動揺補正、潮位補正等を行うことで、最終成果物を作成することができます。
現在、CUBE処理(Combined Uncertainty and Bathymetry Estimator)と呼ばれる統計的手法でのデータ解析が海外の水路機関では主流となっています。CUBE処理を使用する事で、効率よく品質の良いデータを作成することが可能となります。
本記事ではCUBE処理のメリットや主目的について易しく解説を行います。

図1 マルチビーム測深機のイメージ図 (左)
ワイドバンドマルチビーム測深機「Sonic」シリーズ (右)
マルチビーム測量の課題
マルチビーム測量が抱える大きな課題の一つにデータの後処理が挙げられます。従来の処理手法では担当者が測深データをHYPACK等の処理ソフトウェアを使用して、手動で成果物を作成してきました。この方法では成果物の品質が担当者の経験に依存し、個人差が現れます。また、手動処理では大きな労力と時間が必要となります。表1 マルチビーム測深の後処理の課題
| 比較項目 | 従来の手動処理 | CUBE処理 |
|---|---|---|
| データ品質 | 担当者の経験則に依存するためデータ品質が均一でない | コンピュータによる統計処理を行うため、データ品質が均一 |
| 作業時間 | 取得したデータを手動で処理するため、時間がかかる (測量時間よりもデータ処理時間の方が長い。) | 統計処理は自動で行われるため、省時間化できる |
| 精度管理 | 測深データの精度管理が難しい (例:計測精度を考慮しないため、スワス端の精度が悪い値を採用しがち。) | CUBE処理は機器固有の不確かさを定量化し、データそのものが持つランダム性を考慮した上で真の水深値を推定する これらの不確かさが記録として定量的に残る。 |
注意点
CUBE処理はあくまでデータ処理の補助ツールです。データ処理の最終的な責任はデータ処理担当者にあります。CUBEの目的は、データの解釈を行いやすくする事です。
最も重要な事はデータ処理担当者が水路学的能力を養うことであり、もし最終成果物に疑問があれば修正を行う必要があります。
CUBE処理って何?
CUBE処理(Combined Uncertainty and Bathymetry Estimator)は水深推定アルゴリズムによる統計処理の事です。
CUBE処理の目的はマルチビームシステムが持つ精度や、計測データの不確かさを加味する事で真の水深値を推定する事です。マルチビーム測深機による高密度の取得データを最大限利用することで、尤もらしい水深値を推定します。
さて、CUBE処理によるメリットは大きく3つ挙げられます。
① 後処理が担当者の熟練度に依存しないため、データ品質が均一になる
② データ処理の時間が短縮できる。
③ 精度管理ができる
CUBE処理を使用することで、後処理担当者の仕事は取得データをアルゴリズムに入力し出力結果を確認することに変化します。熟練度に依らず均一な品質のデータが出力されることは大きなメリットです。また、最初からノイズ処理を行う必要が無いため、後処理時間を大きく減らすことができます。CUBE処理は機器固有の不確かさを定量化し、データそのものが持つランダム性を考慮した上で真の水深値を推定します。これらの不確かさが記録として定量的に残ります。
CUBE処理とはどういうアルゴリズム?
CUBEアルゴリズムの主目的はデータから可能な限り多くの情報を用いて、調査エリア内の任意の地点における水深値を決定する事です。つまりノイジーな推定値から水深値を、同様に水深値の不確かさを定量的に算出することです。
さて、CUBEでは測定誤差の原因について以下のように明確に区別しています。
- Systematic miscorrection 系統誤差
- Blunders 測定対象に関係しないデータ
- Uncertainty 不確かさ
系統誤差とは、とある原因によって測定値が偏って出力される誤差を指します。例えば、ソナーとGPSアンテナの間のレバーアームのオフセットが正しくない場合などがこれにあたります。CUBEは、すべてのシステム構成機器が正しくオフセット入力されている事を前提としており、オフセット修正をすることはありません。
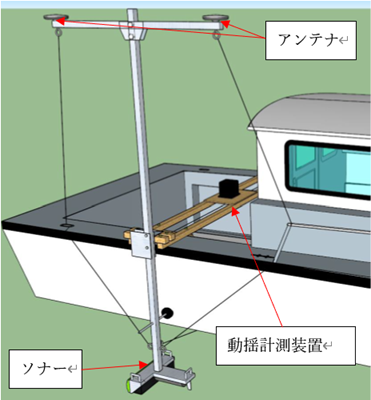
図2 マルチビーム測深システムの艤装例
(上記の構成機器の相対位置を正しく入力できていることが前提)
ブランダーとはマルチビーム測深システム(MBES)が生成する海底面のうち、海底を正しく表現できていないものを指します。これは魚からの反射や、MBESのサイドローブ受信などが原因である可能性があります。CUBEでは、以下の仮定に基づき海底を正しく判定するためのアルゴリズムが設けられています。
- データは海底近傍に密集する
- ノイズ(ブランダー)は低密度で点在する。
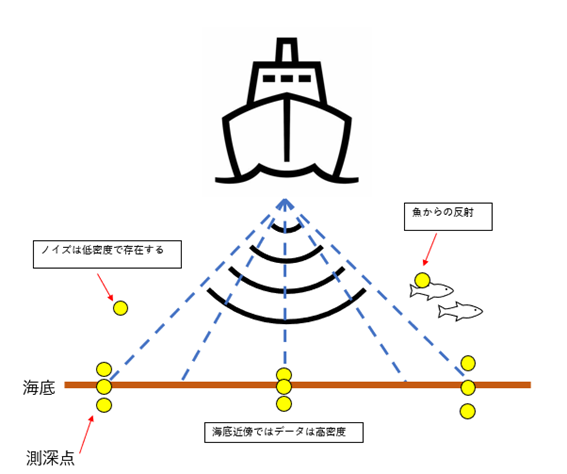
図3 ブランダーデータの例
不確かさとは、取得したデータがもつ値のばらつきの事です。CUBEの最大の関心事は、系統誤差など人的に起因する誤差を除いた、計測システムが持つ不確かさです。すべて適切な補正を行った後に残る測深値のランダムな変動が重要です。これは実データの基本的な性質であり、避けることはできませんが理解し管理することは可能です。この公理が、CUBEのデータに対する考え方とデータ処理の最重要な部分となります。
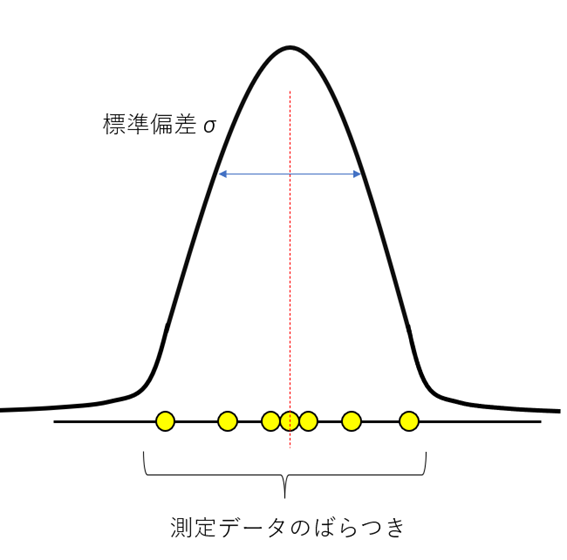
図4 測定データのばらつきと標準偏差のイメージ図
CUBEのデータに対する考え方
すべての測深点はある程度は不確定であり、その地点の水深値の推定を表すものであって、必ずしも「真の深さ」ではないという前提でスタートします。”水深値”がどのくらいなのか、と”水深値の不確かさ”がどの程度なのかという2つの問題に答えるために、どのようにデータを利用するかが重要となります。
CUBEは測深点の不確かさの推定値、不確かさの伝播と組み合わせのモデルを適切に使用することで、もっともらしい水深値を推定します。調査エリア内のどの地点でも、人間のバイアスに影響されず、定量的な統計的裏付けがある、最も可能性の高い水深推定値を出力することができます。このプロセスはアルゴリズムによるものであるため、同じ入力で再現可能であることが保証されています。
しかしながら、アルゴリズムが苦手とする水路状況もあります。水路状況を正しく認識し、必要であれば修正するのは後処理担当者の重要な仕事の1つです。典型的な例としては、沈船の船首のように、深いところに密集したデータの中に浅い測深点がひとつしかないような場合です。アルゴリズムでは浅い点を裏付ける測深点が1つしかないため、統計的に誤る可能性があります。水路学上の注意として、この浅いポイントを適切なマーキングで保存することが必要です。
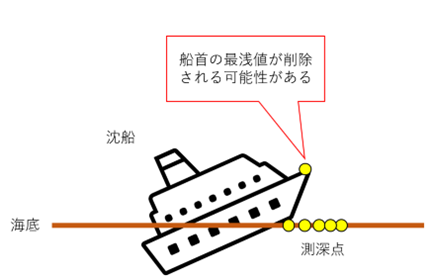
図5 統計処理を行う上で誤りやすい水路状況
まとめ CUBEとは水深値の推定器
CUBEは基本的に水深値の推定器です。マルチビームシステムの構成要素の不確かさを考慮し、最も可能性の高い水深値を推定しようとするものです。CUBEは、均一なデータ品質を保つことが可能で、アルゴリズムの自動処理によって測量の効率化を進めることができます。
次回はCUBEのフローや入力・出力について記載します。